The Rez-County Overlap Layer
This GIS-based layer is a unique output of the Native Lands Advocacy Project and allows us to perform data analysis from datasets that do not match with reservation boundaries or who do not have any common identifiers to match external datasets. This layer is a work in progress and is used with caution to minimize data biases. Its core function is to allow us to use county-level datasets and provide estimates for Native Lands based on the land and population overlap.
Building the Rez-County Overlap
Building the Rez-County Overlap Layer has been an ongoing challenge that involved much thinking, data browsing and GIS processing. The baseline is that we needed a layer that could provide us with least biased estimates to extrapolate county-level data, which is not always possible given the nature of each dataset. The layer allows us to take county-level data and assign it to each county-piece that make up each native land. Here are some of the details and challenges of its building process.
The Base Layer is the result of joining the County and AIAN Census Tiger shapefiles. We first had to consolidate these files as much data was missing and/or mislabeled. We crossed several geography sources to ensure we fix most of the layer errors. We used this base layer a few times to extrapolate county-level averages. However, much work remained, as the base layer did not contain any measures of population or land distribution, which would be essential for other data types.
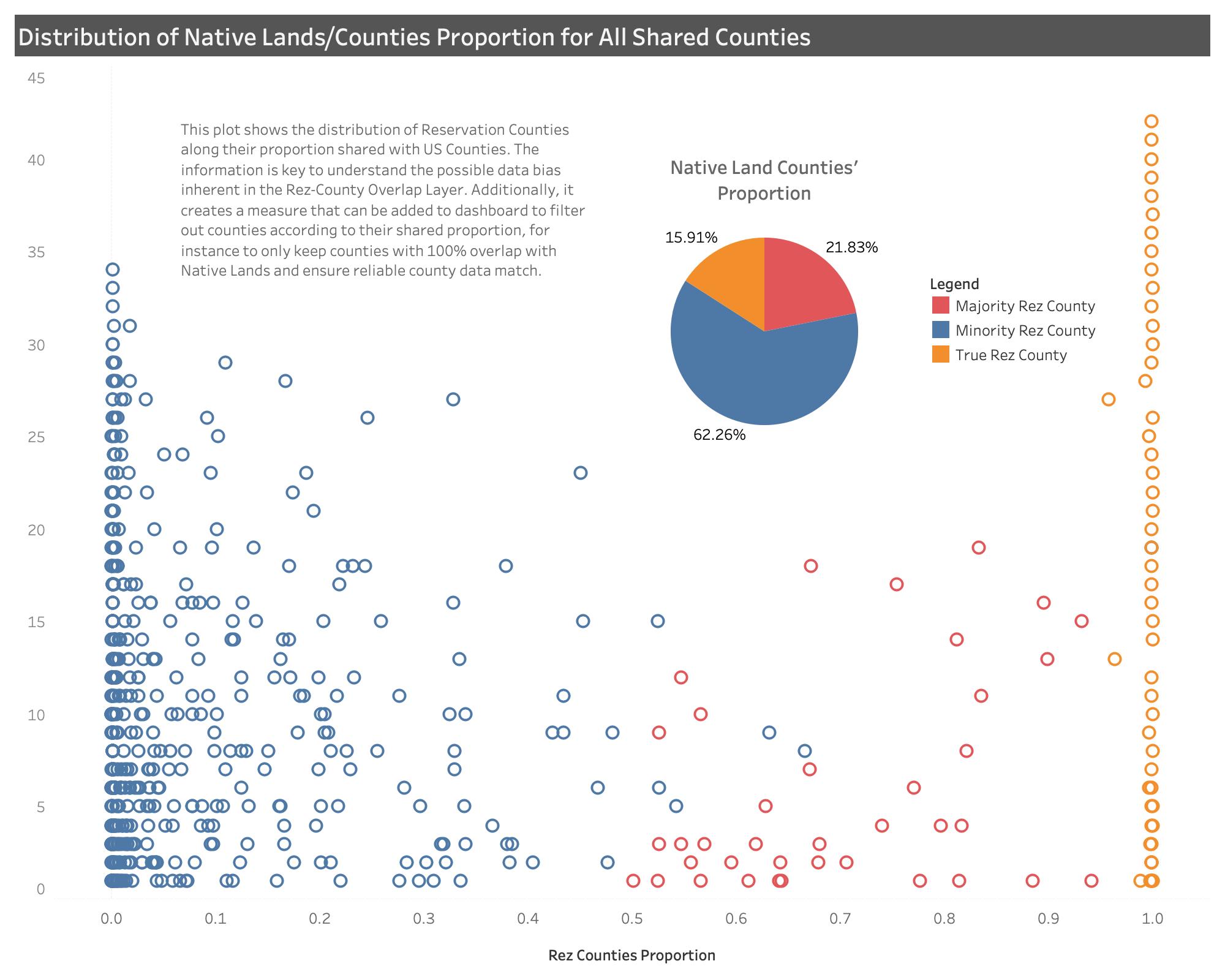
After further processing, we added a land proportion attribute to the data, which gives the proportion of each piece of rez-county to the overall county area (cf. figure below). This feature is useful for processing land-based data. However, it is not suitable for data heavily influenced by demographics. Unfortunately, there is no perfect way to truly know demographics for each rez-county piece. To be completely accurate, such data should be collected by tribes and consolidated into a national layer. Even full-reservation Census figures are largely known to be inaccurate and undercounting reservations’ populations. After thinking about the best methods to reduce Rez-County Overlap biases, we originally thought of simply including a measure of possible neighboring urban centers that could possible impact most demographic-related datasets. But we realized that this was too far an extrapolation, and still was not addressing the issue at stake. We wanted a layer with the least possible error to extrapolate county-level data, we thus needed a measure contrasting each rez-county piece to its corresponding county. We could then use that ratio to apply on raw county-level data to get estimates. We used block-group census data to build this attribute.
Although this methods still does not account for data bias inherent to structural inequality and social-economic variance in the data, this is currently the best proxy available to provide native land estimates of county-level data. Contact us for more details.